数据结构
组织演化模块(PanEvolution)是一个纯面向对象的模块,使用C++语言编写。具有像PanEngine一样的通用数据结构,平衡性能、可维护性和可扩展性。图 1 为析出模块的基本数据结构示意图。 .
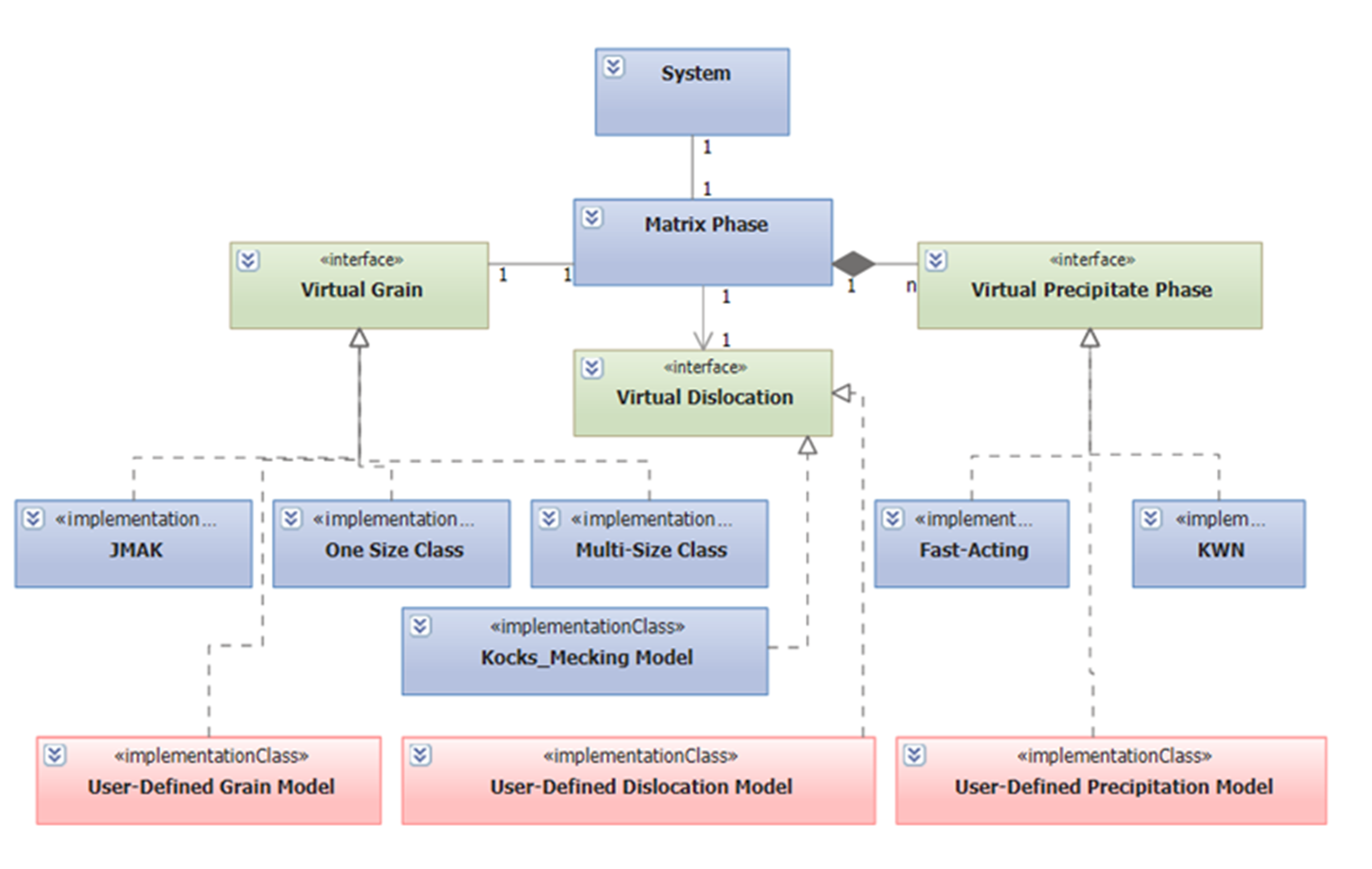
一般来说,一个体系包含一个基体相和若干个析出相。不同析出相的行为可能不同,这就需要不同的动力学模型。另外,计算的速度和模型的复杂程度直接相关。这就需要多级模型以满足不同的需求。目前,PanEvolution模块包括两个内置的模型:Kampmann/Wagner Numerical(KWN)模型和Fast-Acting模型。这种数据结构的突出优点是,可以与其他的析出模型集成在一起,如图 1 所示。用户可以灵活的选择合适的动力学模型,当然,用户可以根据需要选择自己定义模型。
基于上述数据结构,基体相和析出相的输入参数用可扩展的标记语言XML管理,储存在一个“动力学参数数据库”( kdb文件, .kdb) 文件中。XML是一种标准的标记语言,其可扩展性高。按照XML语法,我们专门设计一组标签,来定义每个析出相的动力学模型和模型参数,如界面能、摩尔体积、形核类型,以及形态。并内置了KWN和Fast-Acting两种动力学模型供用户选择。这两种模型都可用来模拟各种形态相(球形和透镜形)的同时析出、同时形核、长大和粗化。对于KWN模型,除了可获得Fast-Acting模型得到的平均尺寸随时间变化、体积分数随时间变化关系外,还可获得不同析出相的粒子尺寸分布(PSD)。因此,本模块中默认采用KWN模型。
说明: 在kdb文件中,用户也可以自定义方程来替代系统内置的模型,这为用户定义的模型提供了数据库/脚本文件级别的插件方法。